

Data engineering is a fundamental field that focuses on designing, developing, and managing systems for efficient data collection, storage, and analysis. Within the Amazon Web Services (AWS) ecosystem, data engineering harnesses a powerful range of cloud services, enabling organizations to fully capitalize on their data resources.
If you want to excel in this career path, then it is recommended that you upgrade your skills and knowledge regularly with the latest AWS Training in Chennai.
Defining AWS Data Engineering
AWS Data Engineering encompasses the methodologies and best practices used to manage and process data through various AWS offerings. Core activities in this discipline include:
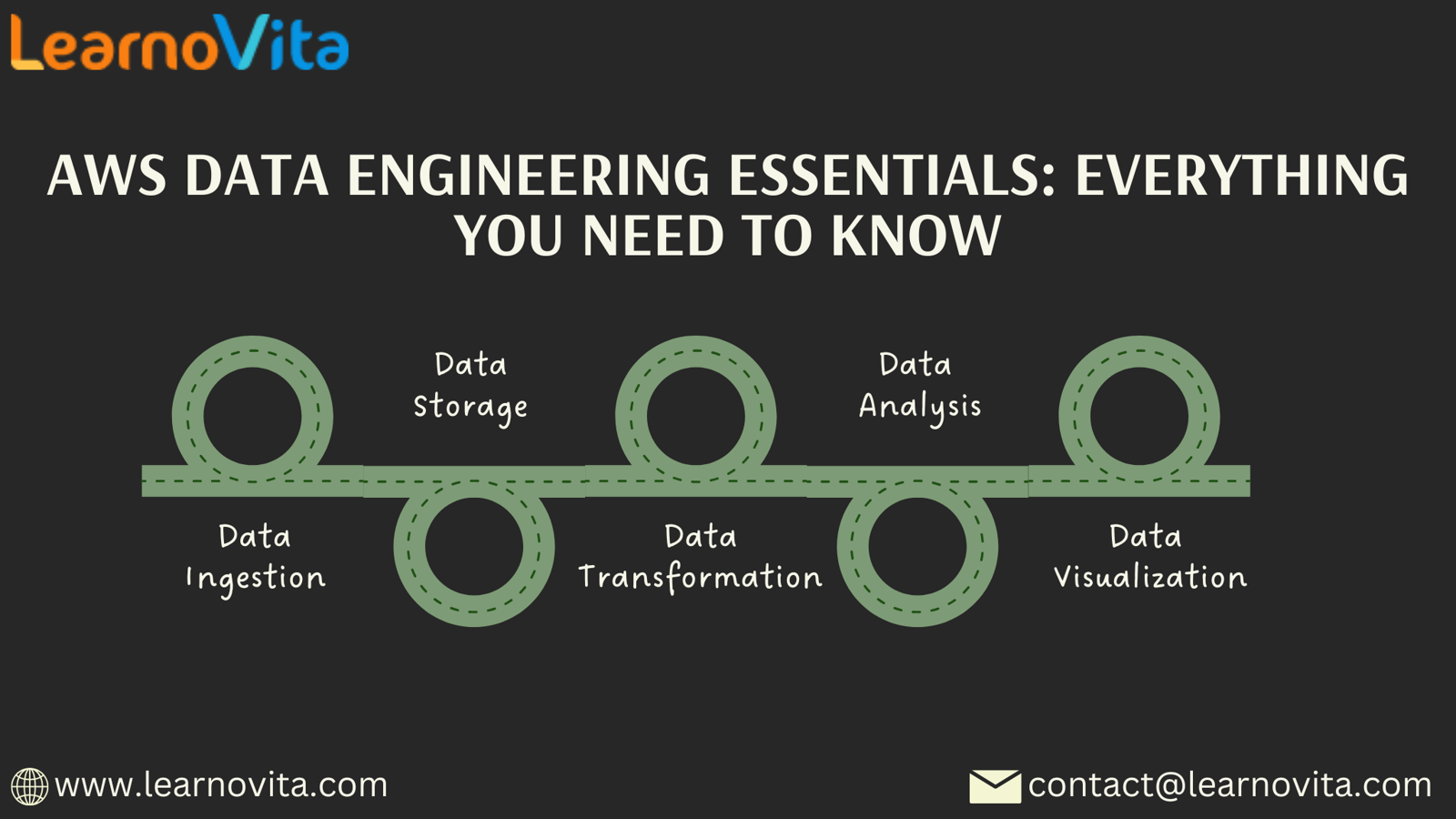
- Data Ingestion: Gathering data from diverse sources, including databases, APIs, and streaming platforms.
- Data Storage: Selecting optimal solutions for effectively managing large datasets.
- Data Transformation: Cleaning and formatting data to enhance its usability.
- Data Analysis: Deriving insights that support informed decision-making.
- Data Visualization: Presenting insights clearly to facilitate stakeholder understanding.
Key AWS Services for Data Engineering
AWS offers a robust suite of services tailored for data engineering tasks. Some of the most important tools include:
- Amazon S3 (Simple Storage Service): A scalable object storage service for easy data management and access.
- AWS Glue: A fully managed ETL (Extract, Transform, Load) service designed to streamline data preparation.
- Amazon Redshift: A high-performance data warehousing solution optimized for rapid querying and analysis.
- Amazon Kinesis: A platform that supports real-time data streaming and processing.
- AWS Lambda: A serverless computing service that executes code in response to events, ideal for varied data processing tasks.
- Amazon EMR (Elastic MapReduce): A managed Hadoop framework that simplifies the processing of large datasets.
It’s simpler to master this tool and progress your profession with the help of Best Training & Placement program, which provide thorough instruction and job placement support to anyone seeking to improve their talents.
Steps to Establish a Robust Data Engineering Pipeline on AWS
Step 1: Data Ingestion
The first step in building a data engineering pipeline is to ingest data from multiple sources. This can involve batch processing (e.g., scheduled data imports) or real-time streaming (e.g., capturing live transactions and logs).
Step 2: Data Storage
After ingestion, it’s essential to choose effective storage solutions. Depending on your organization’s needs, consider utilizing:
- Amazon S3 for raw data storage.
- Amazon RDS for structured data management using SQL.
- Amazon DynamoDB for flexible NoSQL storage options.
Step 3: Data Transformation
Raw data often requires cleaning and transformation before it can be analyzed. AWS Glue automates much of this process, allowing for easy setup of ETL jobs for different data types.
Step 4: Data Analysis
Once the data has been transformed, it is ready for analysis. AWS provides a variety of tools, including Amazon Redshift for data warehousing and Amazon Athena for executing SQL queries on S3-stored data.
Step 5: Data Visualization
Insights gathered from analysis should be effectively visualized. Tools like Amazon QuickSight facilitate the presentation of findings in an accessible format, allowing stakeholders to make informed decisions.
Best Practices for Effective AWS Data Engineering
- Utilize Serverless Solutions: Leverage AWS Lambda and other serverless services to optimize costs and resource management.
- Focus on Security: Ensure data is encrypted in transit and at rest; use AWS IAM to control access to resources.
- Monitor and Optimize: Employ AWS CloudWatch for tracking performance and continuously refining data pipelines.
Conclusion
AWS Data Engineering is crucial for organizations seeking to leverage their data strategically. By utilizing the extensive capabilities of AWS, businesses can develop scalable, efficient, and secure data pipelines that provide valuable insights.